Ich liebe RSS. Schon seit vielen Jahren abonniere ich RSS-Feeds (hauptsächlich bibliothekarische Blogs, aber auch die Feeds von Tageszeitungen und ein paar über persönliche Interessen). So habe ich jeden Morgen und in der Mittagspause die neusten Nachrichten, Gedanken und Ideen in meinem Feed-Reader und bleibe up-to-date.
Viele Jahre war der Google Reader mein RSS-Aggregator. Google Reader ist (noch kann man „ist“ und nicht „war“ schreiben) einfach zu benutzen und egal, mit welchem Rechner oder Browser ich darauf zugriff – der Nachrichtenstrom war genauso wie er war, als ich zuletzt mit einem anderen Rechner oder Browser darauf zugegriffen hatte: die gelesenen Artikel sind als solche gekennzeichnet. Ein anderes Feature, dass ich mag ist, dass Artikel beim rüber scrollen als gelesen gekennzeichnet werden, denn meistens überfliege ich nur die Überschriften und bleibe bei einigen wenigen Artikeln, die mich interessieren hängen.
Aber schon ein paar Monate bevor Google bekannt gab, dass es den Google Reader einstellt, habe ich einen anderen Feed-Reader gesucht. Der wichtigste Grund dafür war, dass ich nicht mehr wollte, dass Google so viel über mich weiß, denn der, der weiß, welche RSS-Feeds ich abonniere und welche Nachrichten ich lese, weiß genau, was mich interessiert, was mich ausmacht. Grundsätzlich weiß ich zwar, dass Privatsphäre im Netz eine Illusion ist und schreibe nur das, bei dem es mir nicht ausmachen würde, wenn die ganze Welt davon erführe (auch bei passwortgeschützten Seiten), aber ein bisschen mehr Privatsphäre wollte ich dann doch.
Also habe ich mich nach Alternativen umgeschaut. Das Blöde ist: Google Reader war so erfolgreich und benutzerfreundlich, dass es kaum noch Alternativen gibt. Wichtige Kriterien waren, dass es ein browser-gesteuerter Reader sein sollte. Die Daten sollten, wie bei Google Reader, irgendwo zentral liegen und ich wollte von überall auf der Welt, egal mit welchem Rechner oder Browser, drauf zugreifen können (Internetverbindung vorausgesetzt). Allerdings wünschte ich mir gleichzeitig ein Programm, dass nur ich alleine kontrolliere, und wo keine Firma oder andere Institutionen ihre Schlüsse über mich ziehen kann. Deshalb waren die üblichen Alternativen zu Google Reader (z.B. hier, hier, und hier beschrieben) für mich keine Alternative.
Von allen Kandidaten blieb nur einer übrig: Fever. Fever hat allerdings zwei Haken im Gegensatz zu allen anderen browser-gesteuerten RSS-Readern: man braucht einen eigenen Webspace um es zu installieren und es kostet etwas. Einen eigenen Webspace habe ich und die 30,00 $ konnte ich verschmerzen. Also habe ich das Programm gekauft und völlig problemlos installiert. Es gibt noch einen weiteren Punkt, der einige abschrecken könnte: das Programm ist in Englisch. Eine deutsche Version gibt es nicht. Das stört mich nicht, da ich sehr viel Englisch lese. Und ich glaube, dass auch die, denen Englisch nicht so geläufig ist, dennoch das Programm nutzen können, denn am Ende geht es um die Inhalte, die man abonniert und alles andere erfordert nur sehr wenige Englisch-Kenntnisse.
Meine RSS-Abos im Google Reader waren schnell exportiert und in Fever importiert. Ich habe Fever passwortgeschützt eingerichtet. So kann niemand außer ich auf die Seite zugreifen und so weiß niemand außer ich, welche RSS-Feeds ich abonniere.
Fever ist zwar nicht ganz so einfach zu bedienen wie der Google Reader, aber ich konnte es bald so einstellen, dass es meinen Lese-Gewohnheiten mehr oder weniger entsprach. Das, was ich am meisten vermisse ist, dass nicht der ganze Artikel geöffnet wird, sondern nur die Überschrift und einen einführenden Text (wenn man unter „Preferences – Display“ „excerpt items“ anklickt). Ein Klick auf den Artikel öffnet ihn dann ganz, so wie er vom RSS-Feed kommt. Einerseits klickt man also mehr, andererseits ist das Ganze auch übersichtlicher und aufgeräumter. Man braucht nicht mehr über ellenlange Artikel, die einen nicht interessieren zu scrollen. Mehr Klick, weniger Scroll.
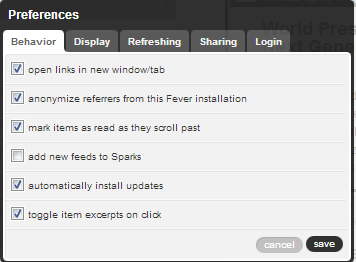
Andere Einstellungen, die ich vorgenommen habe, sind:
Vor allem der Punkt „Mark items as read as they scroll past“ und „toggle item excerpts on click“ sind mir wichtig. Ersteres erspart einen viel Klicken, vor allem wenn man viele Feeds abonniert, aber nur wenige Beiträge wirklich liest. Bei zweiterem öffnet sich der ganze Text des Beitrags in Fever selbst und man braucht den Artikel nicht erst in einem anderen Reiter oder Fenster zu öffnen.
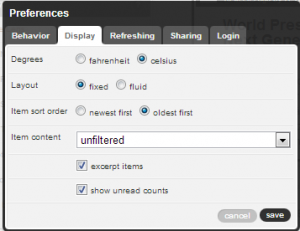
Hier ist mir vor allem „excerpt items“ wichtig, denn so bekomme ich außer der Überschrift auch noch einen kurzen einführenden Text angezeigt, der mir bei der Entscheidung ob ich einen Artikel lesen möchte oder nicht, hilft.
In diesen beiden Screenshots sieht man zwei Aspekte, die man beim Google Reader nicht finden wird: Unter „Behavior“ gibt es eine Einstellung zu „Sparks“ (bei mir nicht angehakt) und unter „Display“ eine Einstellung zu Degrees (bei der ich mich für „Celsius“ entschieden habe). In Fever gibt es nämlich die Möglichkeit, ganz „heiße“ Themen zu ermitteln, Themen also, über die viel geschrieben wird. Ich bin gerade dabei mit dieser Möglichkeit zu experimentieren und werde in einem anderen Beitrag darüber schreiben.
Bereue ich den Umstieg? Nein. Ich merke aber, dass ich ein Gewohnheitstier bin. Jahrelang habe ich den Google Reader fast täglich genutzt und eine Umstellung auf einen anderen Reader erfordert halt auch die Umstellung der Gewohnheiten. Das hätte ich bei den anderen Alternativen auch. Auf jeden Fall bekomme ich mehr als mit Google Reader: mehr Privatsphäre und die Möglichkeit, die wirklich heißen News automatisch heraus zu filtern.

 Drucken und PDF
Drucken und PDF