
So sieht, nach http://personas.media.mit.edu/ mein digitales Portrait aus:
(Klick auf das Bild um eine vergrößerte Version in einem neuen Fenster zu sehen)
Wie kam es zu dem Bild? Webseiten von oder über die angegebene Person werden angeschaut und mit Natural Language Processing bearbeitet. Auf der Website wird der Prozess wie folgt beschrieben:
Enter your name, and Personas scours the web for information and attempts to characterize the person – to fit them to a predetermined set of categories that an algorithmic process created from a massive corpus of data. The computational process is visualized with each stage of the analysis, finally resulting in the presentation of a seemingly authoritative personal profile.
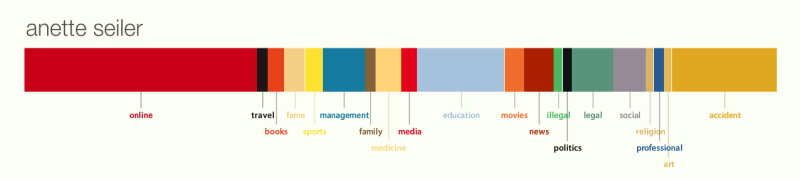
Ich halte das Ergebnis für nicht gut. Natürlich schätzt man sich selbst anders ein als andere (und als Algorithmen), aber auch bei so objektiv wie möglicher Betrachtung, sehe ich viele Fragezeichen. Mein digitales Leben war bisher zweigeteilt: einerseits beschäftige ich mich beruflich als Bibliothekarin viel mit Repositorien, Digitalisierung, Semantic Web, Erschließung, Langzeitarchivierung, Programmierung usw. Anderseits habe ich einiges über Religion (in Zusammenhang mit Sexualität) im Web stehen. Dann noch ein ganz klein bißchen privates, wobei ich das, z.B. über Facebook, auch mehr oder weniger privat halte. Ich würde dem beruflichen 60%, dem religiösen 30% und dem privaten 10% geben.
Die Grafik kategorisiert Information über mich anders. Wenn man „online“, „books“, „education“, „media“ und „professional“ zusammen nimmt, kommt man vielleicht auf die Dinge, die ich als „beruflich“ einschätze. Zusammen würde es wahrscheinlich den größten Block ausmachen. Das religiöse wird nur sehr eingeschränkt wahrgenommen. Das private kann man eventuell mit „travel“ verbinden. Dann gibt es aber eine Menge Blöcke, und einige davon sehr große, mit denen ich gar nichts anfangen kann: „accident“, „education“, „management“, „legal“, „illegal“, „fame“, „medicine“, „movies“, „news“, „social“, „art“ und „sports“. Ja, ich interessiere mich für Film, Kunst, Sport und Nachrichten, aber ich äußere mich kaum dazu. Beruflich habe ich vielleicht mit Mangement, Education und legal/illegal (in der Form von Urheberrecht) zu tun, aber auch darüber habe ich nie was geschrieben. Die Kategorien „accident“ und „fame“ haben nichts mit meinem Leben zu tun. Noch weniger kann ich verstehen, warum „accident“ eine so große Rolle in der Grafik spielt.
Ich fühle mich also von dieser Grafik nicht richtig dargestellt. Woran könnte es liegen? Mir fallen folgende mögliche Gründe ein:
- Information über mich liegt hauptsächlich in deutsch vor. Laut der Erklärung unter „How it Works“ (http://personas.media.mit.edu/personasWeb.html) wird versucht, nicht-Englischen Text zu entfernen. Da bleibt nur sehr wenig übrig.
- Ich bin nicht die einzige Anette Seiler im Internet. Obwohl mein Vorname eher selten ist, gibt es meines Wissens, noch mindestens eine zweite „Anette Seiler“. Allerdings kann ich mich nicht erinnern über sie etwas wie „accident“ gesehen zu haben. Anderseits habe ich schon lange nicht mehr nach unser beider Namen gegoogelt. Jedenfalls kann ich mir vorstellen dass Namen wie „Michael Müller“ oder „John Smith“ kaum aussagekräftige Ergebnisse bringen können
- Wie bereits gesagt: nicht alle Information im Netz über mich ist allen zugänglich (Facebook). Das kann auch dazu führen, dass ein schiefes Bild von mir gezeichnet wird.
Das Experiment möchte zwei Ziele erreichen (siehe unter „Now what“):
- Es möchte den Prozess, der hinter den Web-Kulissen stattfindet, darstellen. Solche statistischen Berechnungen finden oft statt, z.B. auf Partnerschaftswebseiten. Erschreckend ist der Gedanke, dass meine Daten-Geschichte zukünftige Einschätzungen, die andere über mich treffen könnten, beeinflussen kann. Was wäre, wenn ein potentieller Arbeitgeber zum Beispiel bei den Bewerbern auf eine Stelle solche Mechanismen benutzen würde?
- Der Entscheidungsprozess im Ranking von Webseiten ist sehr undurchsichtig – vor allem wenn es darum geht, Geld damit zu verdienen. „Personas is meant to expose this black box process as controlled voodoo.“ heisst es unter „Now what“. Websites, die solche Mechanismen einsetzen, stellen sich selbst oft als sehr authoritativ dar, sind es aber gar nicht. Personas will also zeigen, dass Maschinen nicht so intelligent sind, wie wir es oft vermuten, auch wenn ihre Ergebnisse toll aussehen.
Nun, die Website hat bei mir vor allem das zweite Ziel erreicht. Ich gehöre eher zu den Verfechtern von Suchmaschinentechnologie für die Erschließung von Information. Zur Verfechterin wurde ich, als ich einige sehr überzeugende Ergebnisse demonstriert bekam. War das, was ich gesehen habe „controlled voodoo“? Vielleicht ja, vielleicht nein. Genau die Nachdenklichkeit wollte man erreichen. Wenn man dann sagt: „I am scared!“ so sagen die Entwickler: „Then we did our job!“
 Drucken und PDF
Drucken und PDF