Für mein Studium habe ich einen Aufsatz zum Thema Semantic Web geschrieben. Wer sich dafür interessiert, kann ihn hier downloaden.
Das Semantic Web
1

Für mein Studium habe ich einen Aufsatz zum Thema Semantic Web geschrieben. Wer sich dafür interessiert, kann ihn hier downloaden.
Ich halte Zotero für eines der nützlichsten Programme in meinem Arbeits- und Studiumsleben. Aber ich bin nicht zu 100% glücklich mit Zotero. Mir fehlt z.B. so etwas wie ein Citation Key, eine ID für meine Metadaten zu einem bestimmten Dokument. Das kann irgendwas sein, z.B. eine laufende Nummer. (*) Es gibt auch andere, die sich sowas für Zotero wünschen. Unter ZoteroDev gibt es ein entsprechendes Ticket, aber das neuste Kommentar ist dort auch schon 20 Monate alt. Es steht in den Sternen, ob und wann es mal umgesetzt wird.
Wegen dieser Unzufriedenheit habe ich mir Mendeley installiert. Mendeley hat nämlich die Möglichkeit einen Citation Key zur bibliographischen Beschreibung anzulegen. Man kann diese Keys automatisch erstellen, indem man die Bibliographie als BibTex-Datei exportiert. Änderungen, die man per Hand vornimmt, bleiben bei einer weiteren automatischen Erzeugung erhalten. Und wenn man nach dem Citation Key sucht, findet man das entsprechende Katalogisat. Das ist genau, was ich brauche.
Auf dem ersten Blick ähnelt Mendeley Zotero in vielen Aspekten. Beim genaueren Hinschauen gibt es dann doch Unterschiede. Dazu kommt, dass Mendeley keinesfalls so stabil wie Zotero ist. Doch zu den Unterschieden:
Es ist einfach, eine Webseite in Zotero aufzunehmen: Ein Klick, eventuell ein bißchen Katalogisierung und fertig. Das funktioniert unter Mendeley nicht ohne weiteres. Es gibt eine Verknüpfung, die man in die Lesezeichen-Leiste ablegen kann. Wenn man aber nun z.B. einen Artikel aus dem Kölner Stadtanzeiger in seine Bibliothek aufnehmen möchte, geht das nicht. Der Mendeley Link funktioniert nur bei einigen ausgesuchten Websites wie arxiv oder World Cat, SpringerLink oder ScienceDirect. Wie bei Zotero werden COinS benutzt, aber im Gegensatz zu Zotero nur bei einigen, ausgewählten Websites. Bei den meisten akademischen Repositorien werden trotz eventuell vorhandener COinS diese nicht erkannt. Natürlich kann man dennoch Webseiten aufnehmen, aber das geht nur händisch. Nicht dass man bei Zotero nicht auch Hand anlegen muss – aber manchmal kann man die von Zotero extrahierte Information auch benutzen. Bei Mendeley wird nichts extrahiert. Bei PDF-Dateien gibt es Vorteile bei Mendeley: Das Programm versucht, die Metadaten aus PDF-Dateien zu extrahieren. Aus einem von mir geschriebenen Protokoll, dass ich testweise geladen habe, hat es den Titel erkannt. Bei Zotero war dies nicht möglich. (**)
Aber es gibt ja Abhilfe: man kann seine Zotero-Bibliothek in Mendeley synchronisieren. Das funktioniert nur in die Richtung Zotero nach Mendeley, nicht umgekehrt. Nur erweist sich Mendeley in der Hinsicht noch als sehr fehleranfällig. Ich bekomme zwar die Zotero-Dateien rüber, aber die Tatsache, dass ich mit Zotero synchronisieren möchte, wird nicht gespeichert. Nach der Synchronisation kommt meistens ein Absturz der die Daten zur Synchronisation aus den Optionen löscht.
Wenn man nun aber auf Zotero verzichtet? Dann muss man halt alle Metadaten selber eingeben. Der Katalogisierungsaufwand ist, vor allem wenn man auch Webseiten verwaltet, größer.
Was PDFs betrifft, ist Mendeley Zotero nicht nur in der Metadatenextraktion überlegen: Man kann die geladenen PDFs auf dem Mendeley-Desktop annotieren. Da könnte man es sich fast überlegen, einen PDF-Snapshot einer Website zu erstellen und diesen zu den Metadaten der Webseite dazuzuladen. Da Webseiten sich sehr schnell ändern können, ist eine solche Fixierung vielleicht keine schlechte Idee. Und diese PDF könnte ich dann in Mendeley annotieren.
Mendeley-Desktop ist nicht, wie Zotero, ein Plugin von Firefox, sondern ein separates Programm. Einige mögen das als Nachteil sehen, mich stört es nicht. Im Gegenteil: es macht mich nicht davon abhängig, Firefox zu benutzen. Und außerdem ist das eigenständige Programm übersichtlicher als Zotero. Wenn man Zotero in derselben Übersicht haben möchte, muss man es maximieren, aber dann ist der Browser nicht mehr nutzbar. Zotero als halbes Firefox-Fenster ist ein Kompromiss, der mir nicht wirklich gefällt.
Ein Argument gegen Mendeley ist, dass es ein proprietäres Programm ist. Man liefert sich zu einem gewissen Maße einer Firma aus. Während der Speicherplatz von Zotero nur durch die Größe der webdav-Partition begrenzt wird, ist das Maximum, das man bei Mendeley hochladen kann, 500 MB. Danach braucht man ein Premium-Paket. Im Augenblick bin ich mit meinen Zotero-Dateien bei 115 MB. Aber dieses Limit gilt nur, wenn man seine Daten auf die Mendeley-Website zwecks Synchronisation hochlädt. Man kann Mendeley Desktop auch eigenständig benutzen. Für mich, die ich von mehreren Rechnern an mehreren Orten auf meine bibliographischen Daten zugreifen möchte, geht es aber nicht ohne den Weg über die Mendeley-Website und damit nur mit der Einschränkung. Die Kosten für diese Premium-Pakete sind noch nicht bekannt.
Die Synchronisation zwischen Mendeley-Desktop und meinem Account ist noch nicht optimal. Die Metadaten und die dazugehörige Datei auf dem Desktop werden nicht auf die Website geladen. Es kommt immer wieder zu Fehlermeldungen. Die Metadaten der Website werden auf den Desktop übernommen. Es ist mir nicht möglich, über die Webschnittstelle eine PDF-Datei zu den Metadaten hochzuladen, etwas, was auf dem Desktop ohne weiteres möglich ist. Also brauche ich mir jetzt noch keine Gedanken über Premium-Pakete zu machen: die Dateien werden sowieso nicht synchronisiert.
Durch meine Versuche mit der Zotero- und Mendeley-Website-Synchronisation empfinde ich Mendeley als ziemlich buggy. Das ist nicht weiter verwunderlich, denn es handelt sich um die Programmversion 0.9.4. Da muss man mit Abstürzen und Problemen rechnen. Dennoch werde ich es mal in der nächsten Zeit ohne Zotero-Synchronisation ausprobieren. Mendeley ist es auf jeden Fall wert, dass man es richtig kennenlernt. Zotero werde ich, bei all den Bugs und Fehlermeldungen und Abstürzen jetzt noch nicht deinstallieren.
(*) Der Grund: Ich mache mir oft einen Ausdruck des Artikels. (Ja, ich weiss, es ist nicht cool, Ausdrucke zu machen, aber ich lese sehr viel im Zug und besitze keinen E-Book-Reader) Da würde ich mir am liebsten den Citation Key draufschreiben, damit ich die zum Ausdruck gehörigen Daten schnell und problemlos in Zotero finden kann. Natürlich könnte ich auch nach Autor und Titel suchen, aber wenn man vom selben Autor mehrere Artikel oder Buchkapitel oder Bücher in Zotero beschreibt, ist das auch wieder umständlich. Und dann mache ich mir Notizen zu gelesenen Artikeln oder Webseiten in Word uns speicher sie als RTF ab – und dafür gibt es einen guten Grund: so kann ich nicht nur Textnotizen machen (wie Zotero es erlaubt), sondern auch Bilder. Und außerdem brauche ich die RTF-Dateien auch für andere Zwecke, auf die ich jetzt nicht eingehen möchte. Oder ich zeichne mir ein Bild zu dem Artikel und speicher es ans PNG ab. Als Dateinamen würde ich gerne diesen Citation Key benutzen, so dass ich sofort eine Beziehung zwischen meinem Eintrag in Zotero und zu diesen Dateien erstellen kann. Und auch auf Delicious gebe ich diesen Citation Key in meinen Notizen an und weiss so, dass ich mir die bestimmte URL schon genauer angeschaut habe.
(**) Ein Zitat aus den FAQs zu der Extraktion von Metadaten aus PDFs:
The automatic extraction of document details (authors, title, journal etc.) from a research paper works in several steps.
First, the full text is extracted from the article (currently, only text PDF documents are supported; OCR support for scanned image PDFs is coming soon).
Then, Mendeley Desktop generates a „fingerprint“ from the article’s text. The fingerprint is anonymously sent to the Mendeley server (the server doesn’t store this information and no one can see which articles you are reading). The server checks whether correct document details already exists for this fingerprint and, if that’s the case, downloads it.
If no corresponding fingerprint is found, Mendeley Desktop searches the article’s text for a DOI („Digital Object Identifier“) number. Should it detect a DOI, it queries the CrossRef database for the correct document details.
Finally, if no DOI is found either, Mendeley Desktop uses algorithms to analyze the full text extracted from the article and tries to „guess“ the document details. Unfortunately, it won’t guess correctly 100% of the time. However, if you correct the recognition mistakes, other Mendeley users can benefit from this as well! Here’s how:
As you know, you can back up your Mendeley Desktop library to your account on Mendeley Web. When you do so, the aforementioned fingerprint and the document details which you corrected are uploaded to your account. The Mendeley server aggregates the document details + fingerprints across all user accounts into a completely anonymous common document details pool (also see What about privacy?). So the next time another user runs the same article through the automatic document details extraction, the document details you corrected can be retrieved from the Mendeley server via the fingerprint. In this way, every user benefits from the other users‘ corrections.
So sieht, nach http://personas.media.mit.edu/ mein digitales Portrait aus:
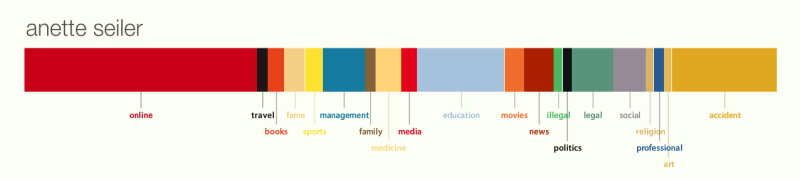
(Klick auf das Bild um eine vergrößerte Version in einem neuen Fenster zu sehen)
Wie kam es zu dem Bild? Webseiten von oder über die angegebene Person werden angeschaut und mit Natural Language Processing bearbeitet. Auf der Website wird der Prozess wie folgt beschrieben:
Enter your name, and Personas scours the web for information and attempts to characterize the person – to fit them to a predetermined set of categories that an algorithmic process created from a massive corpus of data. The computational process is visualized with each stage of the analysis, finally resulting in the presentation of a seemingly authoritative personal profile.
Ich halte das Ergebnis für nicht gut. Natürlich schätzt man sich selbst anders ein als andere (und als Algorithmen), aber auch bei so objektiv wie möglicher Betrachtung, sehe ich viele Fragezeichen. Mein digitales Leben war bisher zweigeteilt: einerseits beschäftige ich mich beruflich als Bibliothekarin viel mit Repositorien, Digitalisierung, Semantic Web, Erschließung, Langzeitarchivierung, Programmierung usw. Anderseits habe ich einiges über Religion (in Zusammenhang mit Sexualität) im Web stehen. Dann noch ein ganz klein bißchen privates, wobei ich das, z.B. über Facebook, auch mehr oder weniger privat halte. Ich würde dem beruflichen 60%, dem religiösen 30% und dem privaten 10% geben.
Die Grafik kategorisiert Information über mich anders. Wenn man „online“, „books“, „education“, „media“ und „professional“ zusammen nimmt, kommt man vielleicht auf die Dinge, die ich als „beruflich“ einschätze. Zusammen würde es wahrscheinlich den größten Block ausmachen. Das religiöse wird nur sehr eingeschränkt wahrgenommen. Das private kann man eventuell mit „travel“ verbinden. Dann gibt es aber eine Menge Blöcke, und einige davon sehr große, mit denen ich gar nichts anfangen kann: „accident“, „education“, „management“, „legal“, „illegal“, „fame“, „medicine“, „movies“, „news“, „social“, „art“ und „sports“. Ja, ich interessiere mich für Film, Kunst, Sport und Nachrichten, aber ich äußere mich kaum dazu. Beruflich habe ich vielleicht mit Mangement, Education und legal/illegal (in der Form von Urheberrecht) zu tun, aber auch darüber habe ich nie was geschrieben. Die Kategorien „accident“ und „fame“ haben nichts mit meinem Leben zu tun. Noch weniger kann ich verstehen, warum „accident“ eine so große Rolle in der Grafik spielt.
Ich fühle mich also von dieser Grafik nicht richtig dargestellt. Woran könnte es liegen? Mir fallen folgende mögliche Gründe ein:
Das Experiment möchte zwei Ziele erreichen (siehe unter „Now what“):
Nun, die Website hat bei mir vor allem das zweite Ziel erreicht. Ich gehöre eher zu den Verfechtern von Suchmaschinentechnologie für die Erschließung von Information. Zur Verfechterin wurde ich, als ich einige sehr überzeugende Ergebnisse demonstriert bekam. War das, was ich gesehen habe „controlled voodoo“? Vielleicht ja, vielleicht nein. Genau die Nachdenklichkeit wollte man erreichen. Wenn man dann sagt: „I am scared!“ so sagen die Entwickler: „Then we did our job!“
Bei der Verbundkonferenz des GBV wurde immer wieder ein Gedanke geäußert, der mich nachdenklich gemacht hat: dass Bibliotheken sich eher um sich selbst, als um ihre Kunden, z.B. die Wissenschaftler kümmern. Beispiel Digitalisierungsprojekte: eine Bibliothek digitalisiert und bringt diese Digitalisate auf ihre Website. Das ist natürlich sehr gut. Wissenschaftler auf der ganzen Welt können nun zur jeder Zeit darauf zugreifen.
Aber kann es nicht noch besser? Immer noch muss ein Wissenschaftler von Website zur Website springen, so wie er früher von Bibliothek zu Bibliothek reisen musste. Dem Wissenschaftler ist es letztendlich egal, aus welcher Bibliothek das Digitalisat kommt. Er wünscht sich einen Zugang zu allen ihm relevanten Digitalisate. Überregionale und themenübergreifende Portale sind also eine Antwort. Nur wird diese Antwort – und das ist nicht nur mein Gefühl, sonst hätte man bei der Konferenz nicht in verschiedenen Kontexten immer wieder davon gesprochen – von den Bibliotheken eher argwönisch betrachtet. Es gibt keine begeisterte Unterstützung dafür. Man kritisiert eher die Deutsche Digitale Bibliothek oder Europeana als dass man über die Chancen dieser Projekte redet.
Das ist einerseits verständlich. Durch ein Bibliotheksportal kann sich die Bibliothek profilieren. Sie kann zeigen: „Schaut her! Wir haben diese tollen Digitalisate! Wir sind eine tolle Einrichtung!“ Eine Bibliothek, die nicht Marketing in eigener Sache führt hat verloren. Gerade heute ist ein Artikel in der FAZ über Ressourcenmangel bei der Herzog August-Bibliothek in Wolfenbüttel. Auch hier wird auf die Digitalisierungsprojekte verwiesen, Projekte, die wissenschaftlich wirklich hochinteressant und wichtig sind, Projekte, die unbedingt gefördert werden müssen.
Diese Profilierung, gerade wenn es um das Lockermachen von Personal und Geld geht, geschieht, indem man sich von anderen Bibliotheken abgrenzt, indem man zeigt, dass man mehr macht, es besser macht als eine andere Institution, die auch im Konkurrenzkampf um die beschränkten Ressourcen steht.
Ich will gar nicht sagen, dass eine Bibliothek nicht ihre eigenen Digitalisate auf ihrer Website darstellen soll. Portalsoftware für Digitalisierungsprojekte, sei es Visual Library, sei es Goobi, sei es irgendeine andere Software, bieten diese Möglichkeit und es wäre dumm, sie nicht einzusetzen. Aber man kann und sollte mehr tun!
Es ist schön, wenn man sagen kann: „Wir haben diese tollen Digitalisate!“ Noch besser ist: „Auf unsere tollen Digitalisate wird n-mal zugegriffen!“ Was bringen die schönsten Digitalisate auf der Bibliothekswebsite, wenn keiner sie benutzt? Richtig unersetzlich macht man sich, wenn man beweisen kann, dass man tatsächlich genutzt wird. Also sollte man sich fragen: „Wie kann ich den Zugriff erhöhen? Wie kann ich mehr Leute dazu bewegen, auf die Digitalisate zuzugreifen?“
SEO gehört dazu. Natürlich will man in Google gefunden werden! Aber wenn es um die Wissenschaftler geht, muss mehr als SEO gemacht werden. Das lässt sich am besten realisieren, indem man dem Wissenschaftler etwas gibt, was er braucht: alles an einer Stelle mit wirklich sinnvollen Tools. Und dieses „alles an einer Stelle“ ist nur möglich, wenn man mit anderen Institutionen zusammenarbeitet. Das ist schwierig, wenn man gleichzeitig im Konkurrenzkampf ist und sich von anderen abgrenzen möchte.
Leider geht der Konkurrenzkampf weiter wenn es um diese Portale geht. Machtspielchen werden gespielt. Zum Beispiel werden die „Großen“, die mit den meisten Digitalisaten und Digitalisierungsprojekten bestimmen wollen, wie das Werkzeug für die Wissenschaftler auszusehen hat. Die anderen müssen es abnicken oder sie bleiben draußen. Und die, die gar nicht digitalisieren, aber sich mit Portalsoftware auskennen (z.B. Verbundzentralen) werden oft ignoriert oder gar bekämpft (denn Verbundzentralen sind ja auch Konkurrenten im Kampf um Ressourcen).
Ich will jetzt gar nicht anfangen von der Profilierungssucht mancher Bibliotheksdirektoren oder -Direktorinnen. Denn dann ist der Vergleich mit dem Dschungel nicht mehr weit.
Jedenfalls glaube ich, dass wenn man sich bei den Wissenschaftlern unersetzlich macht – und das kann keine Bibliothek alleine – viel mehr gewonnen wird, als wenn man erstmal an sich und die eigene Institution denkt.
Neulich las ich einen Artikel von David Pogue, in dem er schrieb, dass sich seine Produktivität dramatisch verbessert hätte, seit dem er die Diktiersoftware Dragon NaturallySpeaking benutzt. Ich habe mich nun eine Weile mit der Beschreibung der Software beschäftigt, hin und her überlegt, da sie nicht ganz preiswert ist, und sie mir schließlich angeschafft, und zwar die Preferred Edition. Die gab es bei Amazon als Schnäppchen.
Die Software wurde installiert, ein Trainingstext musste gesprochen werden und dann konnte es losgehen. Ich muss sagen, dass die Erkennungsrate sehr gut ist. Wenn ein Wort falsch erkannt wird, kann ich es gut nachvollziehen. Entweder habe ich ein Wort benutzt das noch nicht im Wörterbuch aufgenommen wurde, oder ich habe genuschelt. Nach einem Tag kann ich noch nicht sagen dass sich meine Produktivität verbessert hat, denn es gibt noch eine Menge zu lernen, z.B. verschiedene Befehle, mit denen man im Dokument navigiert, oder mit denen man den Text verbessern kann. Und außerdem muss ich noch lernen, auch die Satzzeichen zu diktieren. Aber ich glaube das mit dieser Modus sehr schnell sehr geläufig sein wird.
Ich merke, dass man sehr lange Texte am besten abschnittsweise diktiert und korrigiert. Meine Angewohnheit beim Schreiben mit der Tastatur ist, dass ich den Text erst einmal herunter schreibe und dann von Anfang an verbessere. Dragon hat aber Probleme sich in langen Texten zurechtzufinden, was sich aber auch verstehen kann.
Beim Einsatz einer solchen Software muss man also nicht nur eine lange Latte von Befehlen kennen lernen, sondern auch seine Gewohnheiten ändern. Das ist schon eine gewaltige Umstellung.
Es ist auch möglich einen zweiten Benutzer zu installieren, mit dem man andere Sprachen diktieren kann. So habe ich mir zum Beispiel einen Benutzer für Englisch installiert. Das Problem bei dieser Mehrsprachigkeit ist, dass auch die Befehle in der anderen Sprache gesprochen werden müssen. Man muss also einen noch einen weiteren Satz Befehle lernen. Ich glaube, ich werde eher deutsche Texte diktieren und mich daher auf die deutschen Befehle konzentrieren. Für den englischen Modus werde ich mich auf die Befehle für Satzzeichen beschränken und Veränderung und Verbesserung im Text eher händisch vornehmen.
Die Software kann auch auf mehrere Rechner installiert werden. Zuerst dachte ich, dass bei jedem Rechner der Trainingsprozess von vorne anfangen müsse, aber nun sehe ich, dass man auch Dateien exportieren und importieren kann. Ich habe das noch nicht ausprobiert, aber ich nehme an, dass ich meine Trainings-Dateien von einem Rechner zum anderen überspielen kann. Wenigstens am Anfang wäre das eine tolle Sache.
Wenn mir das Diktieren von Texten geläufig ist, möchte ich Dragon NaturallySpeaking auch für die Steuerung des Rechners und der Programme benutzen. Für solche Zwecke wird die Software auch zum Beispiel bei Behinderten eingesetzt. Auf diese Art und Weise steuere ich im Augenblick die Software selber, indem ich ihr sage das sie schlafen gehen soll wenn ich sie nicht mehr einsetzen möchte, oder dass sie aufwachen soll ich sie wieder benutzen möchte. man kann Menüs öffnen und Menüpunkte ansteuern. Ich sehe mich schon, ähnlich wie Mr. Spock in Star Trek, mit meinen Rechnern sprechen. Aber für solche Aktionen ist die Lernkurve doch sehr steil.
Ich habe eine Bestandsaufnahme der Digitalisierungssammlungen in Deutschland gemacht und die Liste der Sammlungenhier geposted. Feedback ist gerne gesehen, sollte etwas fehlen oder fehlerhaft sein.
Vor etwa einem Jahr habe ich mein Blog von WordPress auf Drupal umgezogen. Nun bin ich wieder auf WordPress. Warum?
Vielleicht sollte ich erstmal erklären, warum ich überhaupt nach Drupal umgezogen war. Ich wollte auf einer Plattform alle meine Webaktivitäten vereinen: Blogs, Webseiten, bibliographische Angaben zu Bücher, Zeitschriften und Websites, Notizen, usw. usf. Drupal erschien mir als eine sehr schöne Lösung für alles. Jedenfalls wollte ich vor allem die Drupal-Module „Blog“, „Biblio“ und „Page“ benutzen. Die Installation war relativ einfach. Mir gefiel Drupal sehr.
Aber, je mehr Inhalt hineingefüllt wurde (und das geschah unsichtbar für nicht-angemeldete Nutzer), desto mehr Probleme gab es. Eigentlich war es nur ein Problem: Error 500 Timeout. Wegen meinem Studium hatte ich lange keine Zeit mich darum zu kümmern, aber es frustrierte mich kolossal. Es war fast nicht möglich, einen Blog-Eintrag zu schreiben, so dass ich mehrmals genervt aufgab.
Nun ist mein Studium vorbei und ich habe mir die Sache mal angeschaut. Im WWW gibt es viele Seiten zu diesem Problem in Verbindung mit meinem Provider (1 und 1). Alles wurde ausprobiert. Nichts half. Wenn man alle Module abschaltet, außer Page, Biblio und Blog verschwindet das Problem. Aber es verschwindet auch eine Menge an Funktionalität.
Also habe ich mir mein Konzept neu überlegt und nach Alternativen geschaut. Andere CMS-Systeme wurden installiert und ausprobiert. Es war alles nicht so das Gelbe vom Ei. Und so bin ich wieder auf das gute alte WordPress gekommen, dass sich in dem letzten Jahr um einiges weiterentwickelt hat. WordPress kann Blog, WordPress kann Webseiten. Und was ist mit Biblio? Das Drupal-Modul Biblio erlaubt es, bibliographische Daten zu Bücher, Artikel, Webseiten usw. zu verwalten. So konnte ich mir z.B. zu einem Artikel Notizen machen. Dafür brauchte ich noch eine Alternative.
Die Alternative heisst Zotero (natürlich!) und Delicious. Auf Zotero speicher ich mir bibliographische Daten zu den Dokumenten ab, die ich tatsächlich lese und studiere, auf Delicious verwalte ich Links zu Dokumenten, die ich vielleicht mal lesen möchte. Da z.B. WorldCat Permalinks zu Büchern anbietet, kann man auch Printmedien über Delicious verwalten. Zotero bietet (nun – vor einem Jahr noch nicht) einiges mehr an Komfort als Biblio.
Nun habe ich mir wieder WordPress installiert und habe meinen Blog und die Webseiten umgezogen. So langsam gehe ich durch meine biblio-Nodes und schiebe sie entweder in Zotero (sehr elegant über COInS – nur ein Klick) oder auf Delicious. Und nun hoffe ich, dass ich in der Zukunft öfters bloggen werde.
War die Entscheidung vor einem Jahr auf Drupal umzuziehen falsch? Nein, ich glaube nicht. Erstens habe ich dieses CMS detailliert kenne- und liebengelernt. Zweitens fehlten vor einem Jahr bei sowohl WordPress als auch Zotero Aspekte, die es nun gibt. Hätte es das Error-500-Problem nicht gegeben wäre ich mit Blog und Webseiten immer noch auf Drupal. Die bibliographischen Daten hätte ich wohl inzwischen mit Zotero verwaltet. Aber WordPress ist auch eine sehr gute und unkompliziertere Alternative zu Drupal. Ich mag sie beide.
Als wir erfuhren, dass die nächste Klausur für unseren Masterstudiengang das „Semantic Web“ zum Thema hat, ging ein großes Stöhnen durch die Reihen der Kommolitonen. Technik! Viel zu viel Technik! hieß es.
Jetzt, wo ich mich in der Prüfungsvorbereitung intensiv mit dem Thema beschäftige, merke ich, dass Technik eigentlich nur marginal vorkommt und zwar in dem Aspekt des Semantic Web, der mit dem „Web“ zu tun hat. Was ist das? HTTP und Unicode. Schon bei XML kann man eigentlich nicht mehr von Technik reden, denn es geht eher um Datenstrukturen. Und all die anderen Komponenten des Semantic Web sind nicht technisch, sondern eher in der Mathematik und/oder Logik oder ganz einfach in der Repräsentation von Wissen verankert.
Gut, da ist noch SPARQL, dass eher an SQL-Abfragen und Datenbanken erinnert. Aber auch hier geht es nicht um Technik an sich. Bei den User Applications – ja da schon.
Doch, es gibt Technik im Semantic Web. Wenn man XML weiterverarbeiten möchte und XSLT oder irgendeine Programmiersprache einsetzt, dann braucht man Informatikerkenntnisse. Aber um das Semantic Web zu verstehen, muss man nicht Informatiker sein. Was nicht heißt, dass es nicht anspruchsvoll ist! Im Gegenteil! Ich komme mit meinen Informatikkenntnissen da auch nicht locker flockig durch.
Es geht eben zu einem ganz großen Teil um Semantik im Semantic Web. Vielleicht nicht um „verstehen“ oder gar um „Intelligenz“ aber doch um die Bedeutung von Dingen.
Ich glaube, ein Hintergrund in der Philosophie, Mathematik und Linguistik hilft mehr, das Semantic Web zu verstehen, als in der Informatik.
Hier meine Folien zum Vortrag über ScanToWeb hosted by hbz. Es ist eine große Datei wegen der vielen Screenshots geworden, aber so kann man die Funktionalität die die Visual Library Software bietet, besser rüberbringen.
Neulich musste ich in der Perspektiv-AG des hbz meine Gedanken zur Zukunft der Kataloganreicherung geben. Hier sind sie:
Ich glaube, dass Kataloganreicherung, so wie wir es jetzt betreiben, nur ein vorübergehendes Phänomen sein wird. Daten wie Inhaltsverzeichnisse sind ein wertvoller Dienst an den Nutzer und steigern die Effizienz der Bibliothek, aber Google zeigt bereits den Trend: Die Endnutzer wollen nicht nur Inhaltsverzeichnisse, sie wollen die Volltexte. Der folgende Satz sollte hier im Raum bleiben, denn ich habe ihn vertraulich erhalten: Stefan Gradmann hat für die DNB ein Gutachten, u.a. über Kataloganreicherung erstellt, und ist genau zu diesem Schluss gekommen: Kataloganreicherung mit Inhaltsverzeichnissen ist nicht das das Ziel, sondern nur eine erste Übung um das zu erreichen, was Nutzer wirklich wollen: Volltextdigitalisierung.
Die Zukunft liegt in der Volldigitalisierung von Büchern und darum sollten wir unseren Fokus noch mehr in diese Richtung wenden. Mit ZVDD und ScanToWeb wurde bereits ein Anfänge gemacht, aber es sind zaghafte Anfänge. Wenn wir in diese Richtung fortgehen wollen, müssten wir die Volltexte nicht nur, über bibliographische Metadaten gut erschlossen, anbieten, sondern auch die Volltexte selbst durchsuchbar machen. Mit der Verbunddatenbank stoßen wir da an unsere Grenzen. Sinnvoll wäre der Einsatz von Suchmaschinentechnologie.
Allerdings hat Kataloganreicherung, so wie wir es betreiben, einen Vorteil gegenüber Volltextindexierung. Inhaltsverzeichnisse geben den Inhalt eines Buches in sehr konzentrierter Form wieder. Der Wortschatz, der dort benutzt wird ist ein sehr relevanter, d.h. Suchen über Inhaltsverzeichnisse führen zu mehr relevanten Treffern als Suchen über den gesamten Volltext. Dies könnte zu einem Vorteil werden, wenn man also nicht nur die Volltexte indexiert, sondern eine weitere Suche auch über Inhaltsverzeichnisse und Register. Ich nenne eine solche Suche jetzt mal „Relevanz Plus“. Das wäre ein Mehrwert gegenüber anderen Suchmaschinen, die Volltexte von Büchern durchsuchbar machen.
Die Digitalisierung von Büchern macht einen Wandel durch. Die DFG macht heute recht strenge Vorgaben, z.B. müssen Strukturdaten erfasst werden. Und genau diese Strukturdaten könnten gebraucht werden um die „Relevanz Plus“-Suche anzubieten.
Was nun von den traditionellen bibliographischen Metadaten? Wenn man so über Volltextindexierung redet, könnte man meinen, sie seien nicht mehr nötig. Das ist aber nicht der Fall. Eine Known-Item-Suche – und die ist bei etablierten Forschern eher der Fall – ist immer noch am besten über bibliographische Metadaten zu händeln. Außerdem brauchen wir bibliothekarische Metadaten für die verschiedenen Workflows in den Bibliotheken. Was ich allerdings als schwierig empfinde ist, dass bibliothekarische Metadaten getrennt von z.B. Volltexten gehändelt werden. Bibliothekarische Systeme wie die Verbunddatenbank können nur die bibliographischen Daten händeln. Die einzige Lösung, die ich sehe ist über Suchmaschinentechnologie. Eine Suchmaschine müsste diese Daten mit Volltexten und differenziertere Suche über Strukturdaten vereinigen.
Wenn wir eine solche Suchmaschine anbieten könnten, und wenn diese Suchmaschine auch noch offen wäre für andere Metadatenformate aus dem Museums- und Archivbereich, wären wir ein ganz heißer Kandidat für die technische Plattform für die Deutsche Digitale Bibliothek.
Eine weitere Möglichkeit der Kataloganreicherung möchte ich noch ansprechen, die vor allem damit zu tun hat, dass nur 20% unserer Titel sacherschlossen sind: Web 2.0-Funktionalitäten wie Tagging und Annotationen. Es gibt bereits Möglichkeiten solche Features auch anzubieten, z.B. durch eine Verknüpfung mit LibraryThing, aber dadurch wird diese Funktionalität und die Vorteile, die diese Funktionalitäten bieten, z.B. eine Suche über Tags, ausgelagert. Anderseits ist es auch unsinnig, dass jeder Verbund oder Bibliothek für sich diese Funktionalitäten entwickelt, denn sie sind nur wirklich gut, wenn Masse da ist. Hier würde ein zentrales Repository wirklich sinnvoll. Aber diese Überlegungen sind noch sehr unausgegoren. Es wäre aber vielleicht eine Möglichkeit einen weiteren Mehrwert für die Endnutzer anzubieten und müsste deswegen untersucht werden.